
Python之Turtle模块 python
常用命令
窗体和画布
# 窗体大小
turtle.setup(宽, 高, x坐标=屏幕居中, y坐标=屏幕居中)
# 画布大小
turtle.screensize(宽, 高, 色)
turtle.screensize() # 默认:400 × 300
画笔
turtle.pensize(粗细) # 笔粗
turtle.width(粗细) # 笔粗
turtl...
boost的字符串操作 c/c++
头文件
#include <boost/algorithm/string.hpp>
功能
字符串切割
boost::algorithm::split()
using namespace boost::algorithm;
int main()
{
std::string s = "Boost C++ Libraries";
s...
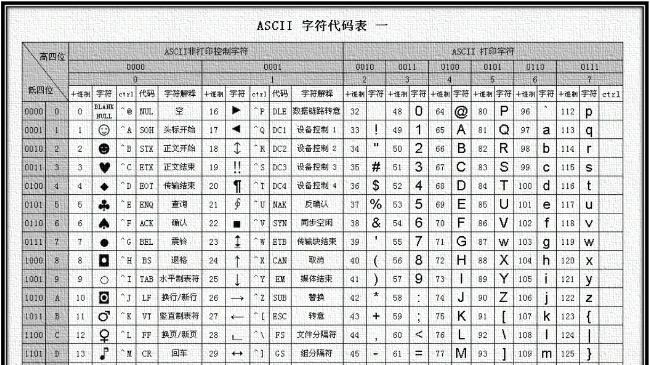
c++程序的编码与字符集的转换 c/c++
一、程序相关的编码
程序源文件编码
程序源文件编码是指保存程序源文件内容所使用的编码方案,该编码方案可在保存文件的时候自定义。
通常在简体中文windows环境下,各种编辑器(包括visual studio)新建文件缺省编码都是GB18030。
所以不特别指定的话,在windows环境下,c++源文件的编码通常为GB18030(GB18030兼容GBK)...

mysql的进阶用法 mysql
视图
类似临时表取别名,可反复使用。不推荐使用
-- 创建
create view v1 as select * from student where sid > 10;
-- 使用
select * from v1; # 使用v1视图
-- 修改
alter view v1 as SQL;
-- 删除
drop view v1;
触发器(不...
mysql的备份与还原 mysql
备份
>mysqldump -u root db1 > db1.sql -p # 无-d参数,备份结构与数据
>mysqldump -u root -d db1 > db1.sql -p # 有-d参数,只备份结构
导入
create database db2; # 先建立数据库
>mysqldump -u用户...
mysql的增删改查 mysql
增 Insert
insert into t1(id, name) value(1, '张三');
insert into t1(name, age) value('张三', 17), ('李四', 18);
insert into t1(name, age) select name, age from t2;
删 Delete
delete from t1...
mysql的数据类型 mysql
数字类型
整数
类型
范围
tinyint
-128 ~ 127
tinyint unsigned
0 ~ 255
smallint
-32768 ~ 32767
smallint unsigned
0 ~ 65535
int
-2147483648 ~ 2147483647
int unsigned
0 ~ 42949...
mysql的索引与外键 mysql
主键索引
约束:不能重复且不能为空;
加速查找
id int unsigned auto_increment primary key,
primary key (id,name), # 多列主键
唯一索引
约束:不能重复,可以为空;
加速查找
unique 约束名 (id, name),
外键
约束:值必须是另一张表的主键
constraint ...

benojan